Introduction
This vignette demonstrates a complete workflow for species
distribution modeling (SDM) for a single species using
h3sdm. We cover data preparation, model fitting, spatial
cross-validation, prediction, and feature importance.
2. Load Environmental Predictors
bio <- terra::rast(system.file("extdata", "bioclim_current.tif", package = "h3sdm"))
names(bio) <- gsub(".*bio_", "bio", names(bio))3. Create the Hexagonal Grid
The hexagonal grid is the backbone of the h3sdm
workflow. All subsequent steps — predictor extraction, presence
assignment, and pseudo-absence generation — are built on top of it. The
resolution controls the spatial scale of the analysis. At resolution 7,
each hexagon covers approximately 514 ha, which is appropriate for many
vertebrate species.
h7 <- h3sdm_get_grid(cr, res = 7)4. Prepare Predictors
Environmental variables are extracted for every hexagon in the grid. Here we use three WorldClim bioclimatic variables: Bio1 (Annual Mean Temperature), Bio12 (Annual Precipitation), and Bio15 (Precipitation Seasonality).
bio_predictors <- h3sdm_extract_num(bio, h7)
#> | | | 0% | | | 1% | |= | 1% | |= | 2% | |== | 2% | |== | 3% | |== | 4% | |=== | 4% | |=== | 5% | |=== | 6% | |==== | 6% | |==== | 7% | |===== | 7% | |===== | 8% | |===== | 9% | |====== | 9% | |====== | 10% | |====== | 11% | |======= | 11% | |======= | 12% | |======== | 12% | |======== | 13% | |======== | 14% | |========= | 14% | |========= | 15% | |========= | 16% | |========== | 16% | |========== | 17% | |=========== | 17% | |=========== | 18% | |=========== | 19% | |============ | 19% | |============ | 20% | |============= | 20% | |============= | 21% | |============= | 22% | |============== | 22% | |============== | 23% | |============== | 24% | |=============== | 24% | |=============== | 25% | |================ | 25% | |================ | 26% | |================ | 27% | |================= | 27% | |================= | 28% | |================= | 29% | |================== | 29% | |================== | 30% | |=================== | 30% | |=================== | 31% | |=================== | 32% | |==================== | 32% | |==================== | 33% | |==================== | 34% | |===================== | 34% | |===================== | 35% | |====================== | 35% | |====================== | 36% | |====================== | 37% | |======================= | 37% | |======================= | 38% | |======================= | 39% | |======================== | 39% | |======================== | 40% | |========================= | 40% | |========================= | 41% | |========================= | 42% | |========================== | 42% | |========================== | 43% | |=========================== | 43% | |=========================== | 44% | |=========================== | 45% | |============================ | 45% | |============================ | 46% | |============================ | 47% | |============================= | 47% | |============================= | 48% | |============================== | 48% | |============================== | 49% | |============================== | 50% | |=============================== | 50% | |=============================== | 51% | |=============================== | 52% | |================================ | 52% | |================================ | 53% | |================================= | 53% | |================================= | 54% | |================================= | 55% | |================================== | 55% | |================================== | 56% | |================================== | 57% | |=================================== | 57% | |=================================== | 58% | |==================================== | 58% | |==================================== | 59% | |==================================== | 60% | |===================================== | 60% | |===================================== | 61% | |====================================== | 61% | |====================================== | 62% | |====================================== | 63% | |======================================= | 63% | |======================================= | 64% | |======================================= | 65% | |======================================== | 65% | |======================================== | 66% | |========================================= | 66% | |========================================= | 67% | |========================================= | 68% | |========================================== | 68% | |========================================== | 69% | |========================================== | 70% | |=========================================== | 70% | |=========================================== | 71% | |============================================ | 71% | |============================================ | 72% | |============================================ | 73% | |============================================= | 73% | |============================================= | 74% | |============================================= | 75% | |============================================== | 75% | |============================================== | 76% | |=============================================== | 76% | |=============================================== | 77% | |=============================================== | 78% | |================================================ | 78% | |================================================ | 79% | |================================================ | 80% | |================================================= | 80% | |================================================= | 81% | |================================================== | 81% | |================================================== | 82% | |================================================== | 83% | |=================================================== | 83% | |=================================================== | 84% | |==================================================== | 84% | |==================================================== | 85% | |==================================================== | 86% | |===================================================== | 86% | |===================================================== | 87% | |===================================================== | 88% | |====================================================== | 88% | |====================================================== | 89% | |======================================================= | 89% | |======================================================= | 90% | |======================================================= | 91% | |======================================================== | 91% | |======================================================== | 92% | |======================================================== | 93% | |========================================================= | 93% | |========================================================= | 94% | |========================================================== | 94% | |========================================================== | 95% | |========================================================== | 96% | |=========================================================== | 96% | |=========================================================== | 97% | |=========================================================== | 98% | |============================================================ | 98% | |============================================================ | 99% | |=============================================================| 99% | |=============================================================| 100%
predictors <- h3sdm_predictors(bio_predictors) |>
dplyr::select(h3_address, bio1, bio12, bio15, geometry)
ggplot() +
theme_minimal() +
geom_sf(data = predictors, aes(fill = bio1)) +
scale_fill_viridis_c(option = "B")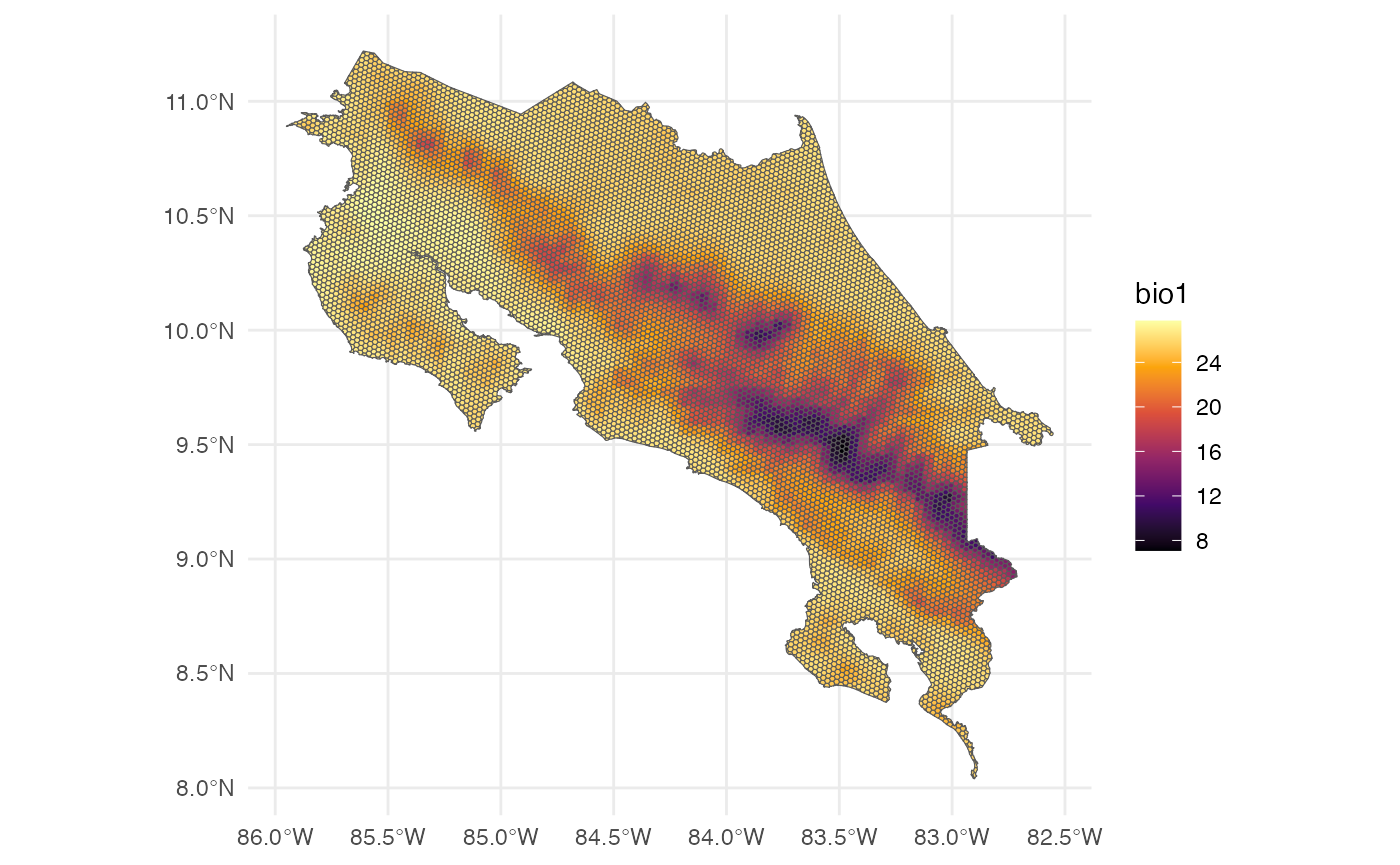
5. Species Occurrence Data
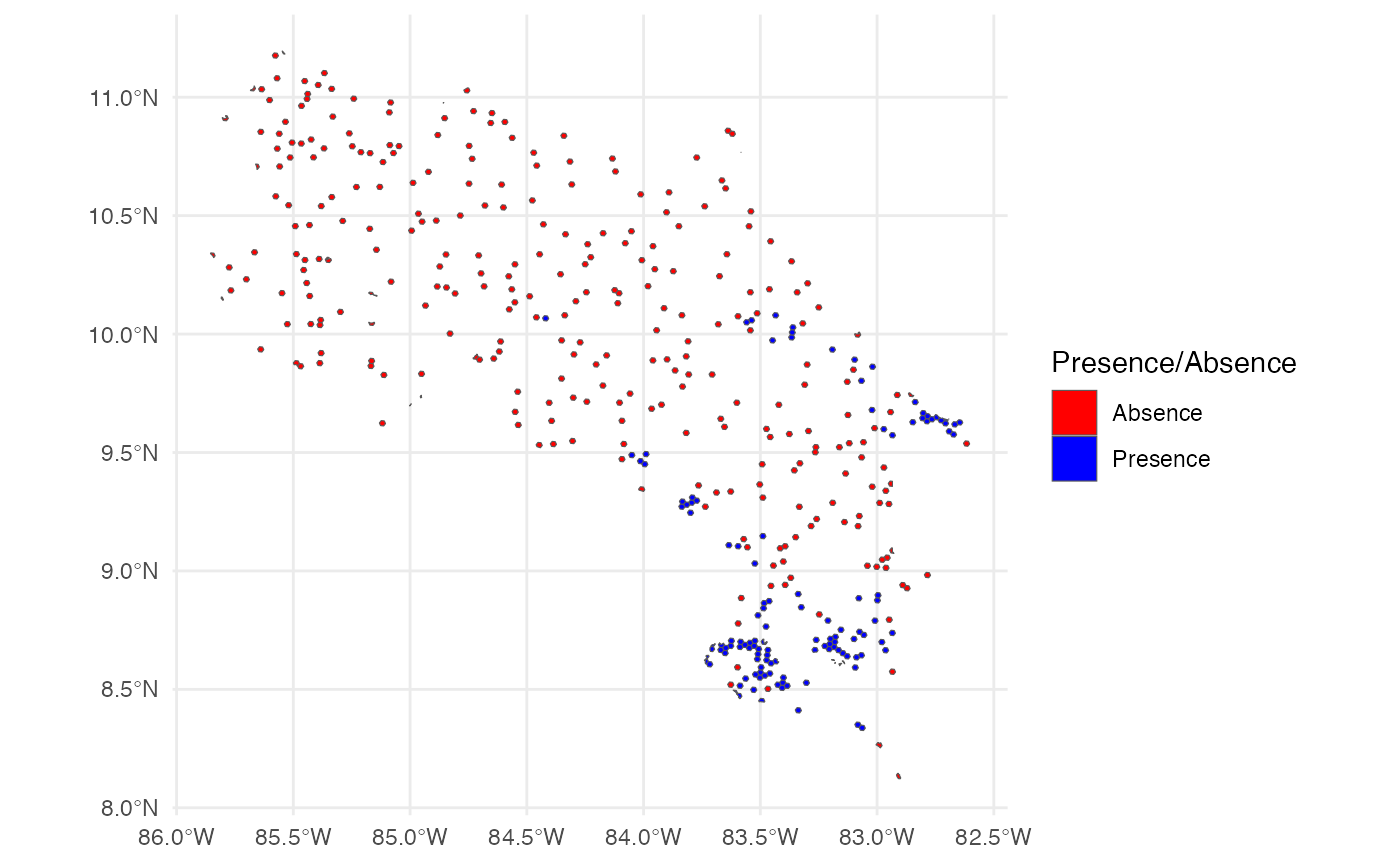
Presence hexagons are generated using h3sdm_pres(),
which downloads occurrence records and assigns them to hexagons.
Multiple records within the same hexagon are consolidated into a single
presence, reducing spatial sampling bias. Since each hexagon represents
an area (~514 ha at resolution 7), this better reflects how organisms
actually occupy space.
Pseudo-absences are then generated with h3sdm_pa(). They
are placed outside the known distribution — excluding hexagons with
presences and their immediate neighbors (buffer_k = 1) —
and are selected using k-means clustering in environmental space. This
ensures pseudo-absences represent the full range of environmental
conditions available in the study area, not just their geographic
distribution. Since there are approximately 100 presence hexagons, we
request 300 pseudo-absences (3×).
pres <- h3sdm_pres("Silverstoneia flotator", cr, res = 7, limit = 10000)
records <- h3sdm_pa(pres, predictors, n_pseudoabs = 300)
table(records$presence)
#>
#> 0 1
#> 300 127
ggplot() +
theme_minimal() +
geom_sf(data = records, aes(fill = presence)) +
scale_fill_manual(
name = "Presence/Absence",
values = c("red", "blue"),
labels = c("Absence", "Presence")
)
6. Combine Records and Predictors
dat <- h3sdm_data(records, predictors)7. Spatial Cross-Validation
scv <- h3sdm_spatial_cv(dat, v = 5, repeats = 1)
autoplot(scv) + theme_minimal()
8. Define Recipe and Model
receta <- h3sdm_recipe(dat) |>
themis::step_downsample(presence)
modelo <- parsnip::logistic_reg() |>
parsnip::set_engine("glm") |>
parsnip::set_mode("classification")9. Create Workflow
wf <- h3sdm_workflow(modelo, receta)10. Fit the Model
presence_data <- dat |>
dplyr::filter(presence == 1)
f <- h3sdm_fit_model(wf, scv, presence_data)11. Evaluate Model Performance
evaluation_metrics <- h3sdm_eval_metrics(
fitted_model = f$cv_model,
presence_data = presence_data
)
evaluation_metrics
#> # A tibble: 8 × 6
#> .metric .estimator mean std_err conf_low conf_high
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 accuracy binary 0.721 0.0545 0.614 0.827
#> 2 f_meas binary 0.754 0.0578 0.641 0.867
#> 3 kap binary 0.309 0.103 0.107 0.512
#> 4 roc_auc binary 0.724 0.0595 0.608 0.841
#> 5 sens binary 0.655 0.0660 0.526 0.785
#> 6 spec binary 0.860 0.0419 0.778 0.942
#> 7 tss binary 0.549 NA NA NA
#> 8 boyce binary 0.675 NA NA NA
ggplot(evaluation_metrics, aes(.metric, mean)) +
theme_minimal() +
geom_col(width = 0.03, color = "dodgerblue3", fill = "dodgerblue3") +
geom_point(size = 3, color = "orange") +
ylim(0, 1)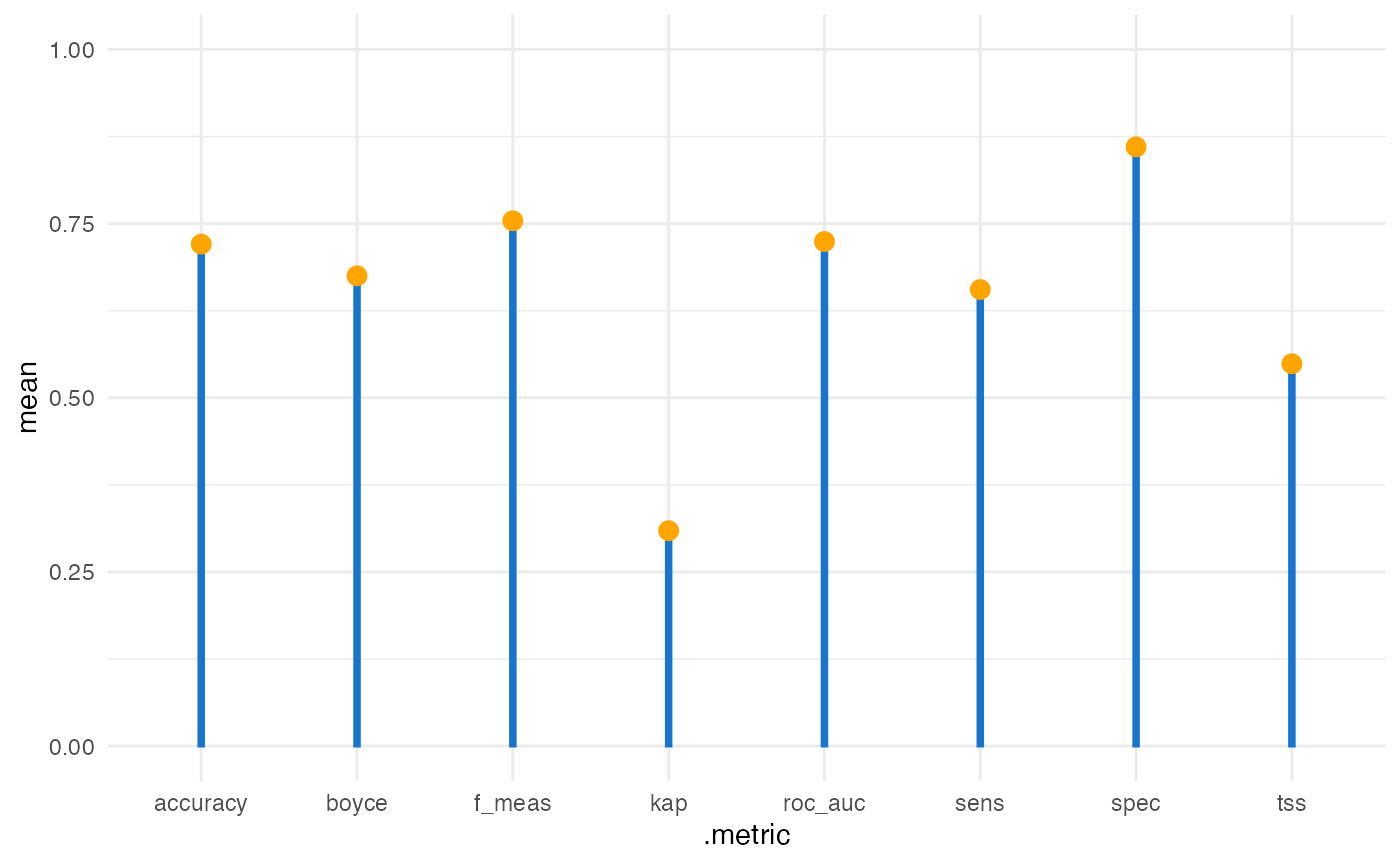
12. Make Predictions
p <- h3sdm_predict(f, predictors)
ggplot() +
theme_minimal() +
geom_sf(data = p, aes(fill = prediction)) +
scale_fill_viridis_c(name = "Habitat\nsuitability", option = "B", direction = -1)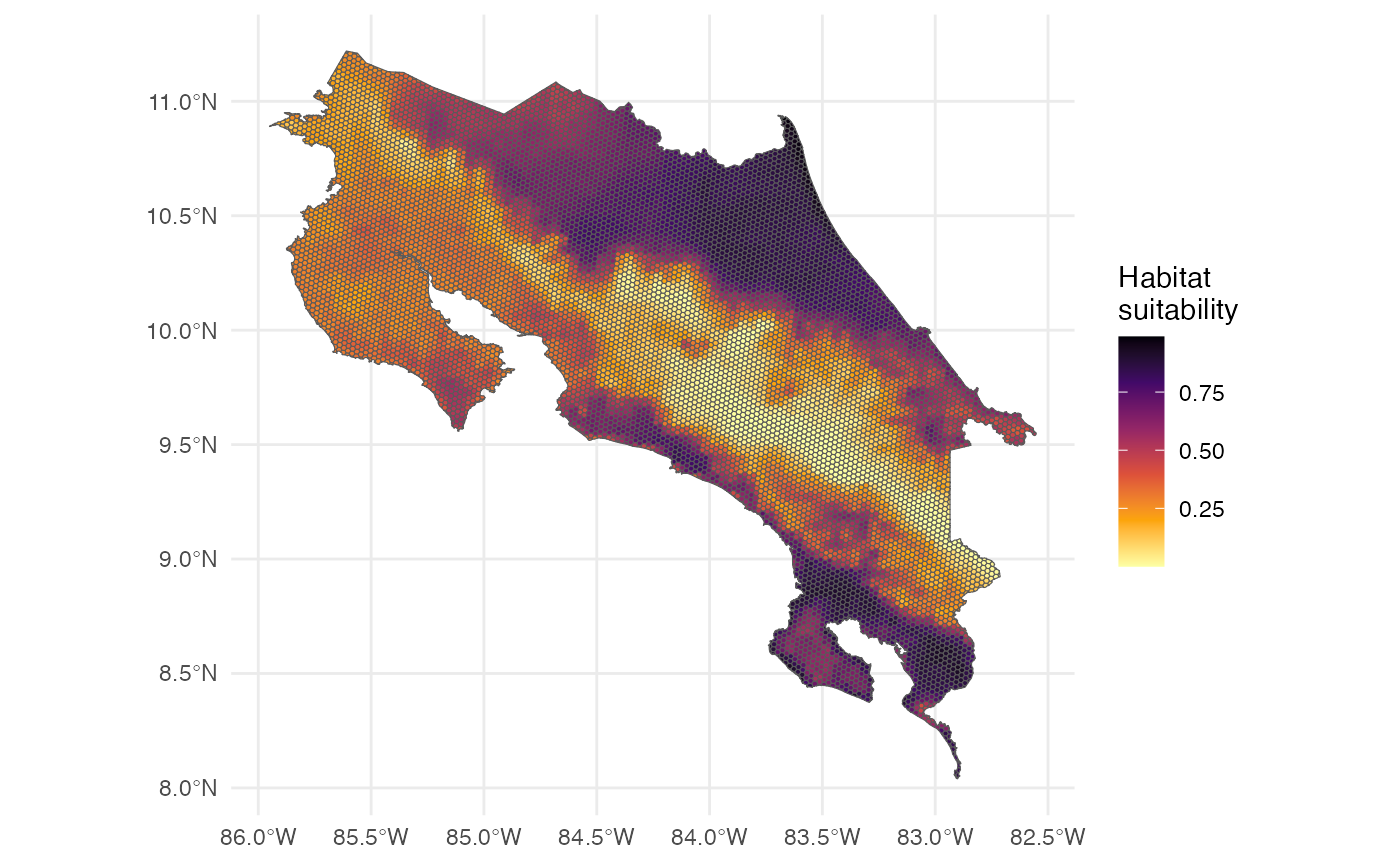
13. Model Interpretation
e <- h3sdm_explain(f$final_model, data = dat)
#> Preparation of a new explainer is initiated
#> -> model label : h3sdm workflow
#> -> data : 427 rows 6 cols
#> -> target variable : 427 values
#> -> predict function : custom_predict
#> -> predicted values : No value for predict function target column. ( default )
#> -> model_info : package Model of class: workflow package unrecognized , ver. Unknown , task regression ( default )
#> -> predicted values : numerical, min = 0.0005692836 , mean = 0.462194 , max = 0.9829601
#> -> residual function : difference between y and yhat ( default )
#> -> residuals : numerical, min = -0.9829601 , mean = -0.1647701 , max = 0.876004
#> A new explainer has been created!
predictors_to_evaluate <- setdiff(names(e$data), c("h3_address", "x", "y", "presence"))
var_imp <- DALEX::model_parts(
explainer = e,
variables = predictors_to_evaluate
)
plot(var_imp)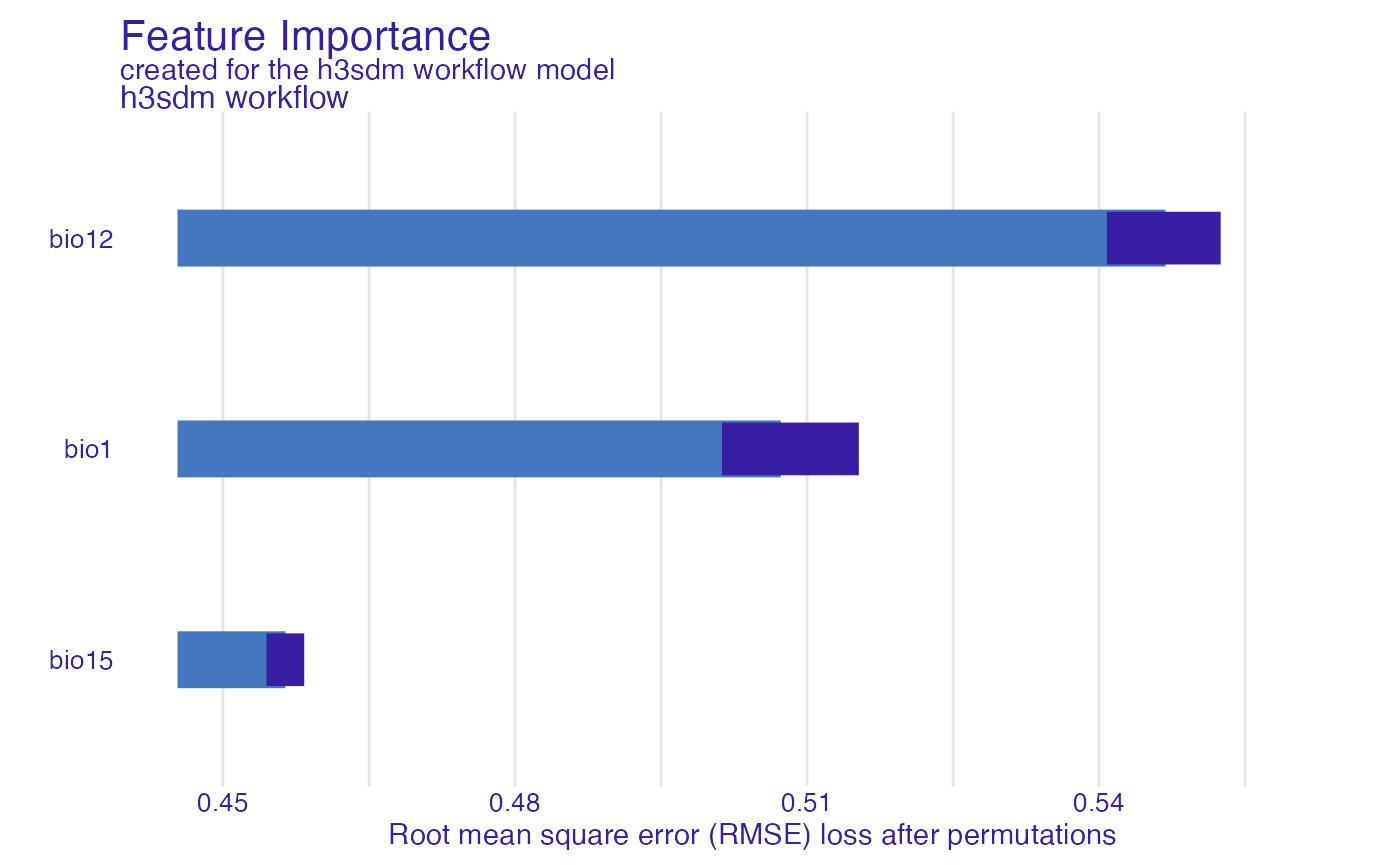
pdp_glm <- ingredients::partial_dependence(e, variables = c("bio12", "bio1", "bio15"))
plot(pdp_glm)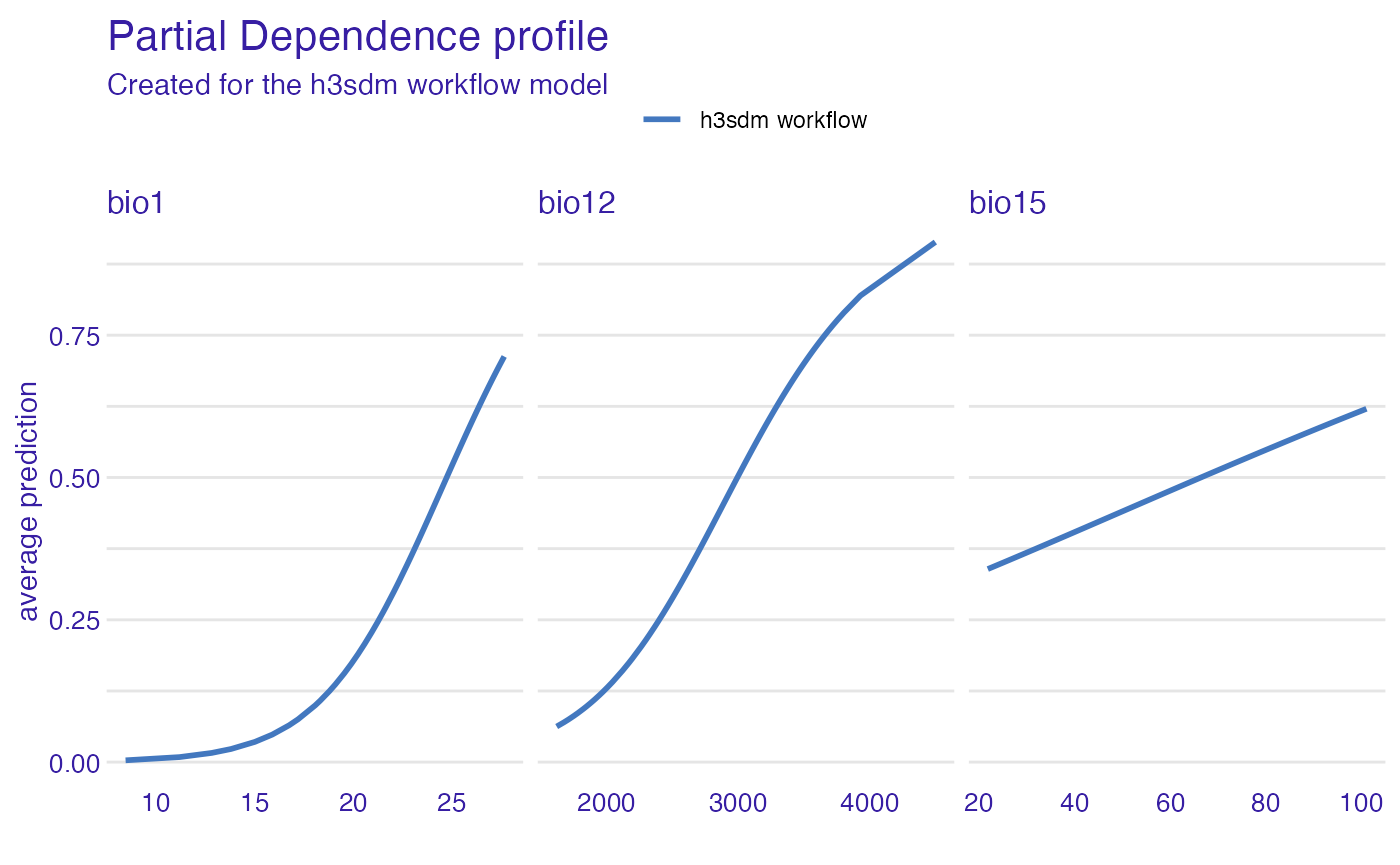
14. Future Scenario Predictions
bio_future <- terra::rast(system.file("extdata", "bioclim_future.tif", package = "h3sdm"))
names(bio_future) <- c("bio1", "bio12", "bio15")
bio_future_predictors <- h3sdm_extract_num(bio_future, h7)
#> | | | 0% | | | 1% | |= | 1% | |= | 2% | |== | 2% | |== | 3% | |== | 4% | |=== | 4% | |=== | 5% | |=== | 6% | |==== | 6% | |==== | 7% | |===== | 7% | |===== | 8% | |===== | 9% | |====== | 9% | |====== | 10% | |====== | 11% | |======= | 11% | |======= | 12% | |======== | 12% | |======== | 13% | |======== | 14% | |========= | 14% | |========= | 15% | |========= | 16% | |========== | 16% | |========== | 17% | |=========== | 17% | |=========== | 18% | |=========== | 19% | |============ | 19% | |============ | 20% | |============= | 20% | |============= | 21% | |============= | 22% | |============== | 22% | |============== | 23% | |============== | 24% | |=============== | 24% | |=============== | 25% | |================ | 25% | |================ | 26% | |================ | 27% | |================= | 27% | |================= | 28% | |================= | 29% | |================== | 29% | |================== | 30% | |=================== | 30% | |=================== | 31% | |=================== | 32% | |==================== | 32% | |==================== | 33% | |==================== | 34% | |===================== | 34% | |===================== | 35% | |====================== | 35% | |====================== | 36% | |====================== | 37% | |======================= | 37% | |======================= | 38% | |======================= | 39% | |======================== | 39% | |======================== | 40% | |========================= | 40% | |========================= | 41% | |========================= | 42% | |========================== | 42% | |========================== | 43% | |=========================== | 43% | |=========================== | 44% | |=========================== | 45% | |============================ | 45% | |============================ | 46% | |============================ | 47% | |============================= | 47% | |============================= | 48% | |============================== | 48% | |============================== | 49% | |============================== | 50% | |=============================== | 50% | |=============================== | 51% | |=============================== | 52% | |================================ | 52% | |================================ | 53% | |================================= | 53% | |================================= | 54% | |================================= | 55% | |================================== | 55% | |================================== | 56% | |================================== | 57% | |=================================== | 57% | |=================================== | 58% | |==================================== | 58% | |==================================== | 59% | |==================================== | 60% | |===================================== | 60% | |===================================== | 61% | |====================================== | 61% | |====================================== | 62% | |====================================== | 63% | |======================================= | 63% | |======================================= | 64% | |======================================= | 65% | |======================================== | 65% | |======================================== | 66% | |========================================= | 66% | |========================================= | 67% | |========================================= | 68% | |========================================== | 68% | |========================================== | 69% | |========================================== | 70% | |=========================================== | 70% | |=========================================== | 71% | |============================================ | 71% | |============================================ | 72% | |============================================ | 73% | |============================================= | 73% | |============================================= | 74% | |============================================= | 75% | |============================================== | 75% | |============================================== | 76% | |=============================================== | 76% | |=============================================== | 77% | |=============================================== | 78% | |================================================ | 78% | |================================================ | 79% | |================================================ | 80% | |================================================= | 80% | |================================================= | 81% | |================================================== | 81% | |================================================== | 82% | |================================================== | 83% | |=================================================== | 83% | |=================================================== | 84% | |==================================================== | 84% | |==================================================== | 85% | |==================================================== | 86% | |===================================================== | 86% | |===================================================== | 87% | |===================================================== | 88% | |====================================================== | 88% | |====================================================== | 89% | |======================================================= | 89% | |======================================================= | 90% | |======================================================= | 91% | |======================================================== | 91% | |======================================================== | 92% | |======================================================== | 93% | |========================================================= | 93% | |========================================================= | 94% | |========================================================== | 94% | |========================================================== | 95% | |========================================================== | 96% | |=========================================================== | 96% | |=========================================================== | 97% | |=========================================================== | 98% | |============================================================ | 98% | |============================================================ | 99% | |=============================================================| 99% | |=============================================================| 100%
predictors_future <- h3sdm_predictors(bio_future_predictors)
p_future <- h3sdm_predict(f, predictors_future)
ggplot() +
theme_minimal() +
geom_sf(data = p_future, aes(fill = prediction)) +
scale_fill_viridis_c(name = "Habitat\nsuitability", option = "B", direction = -1)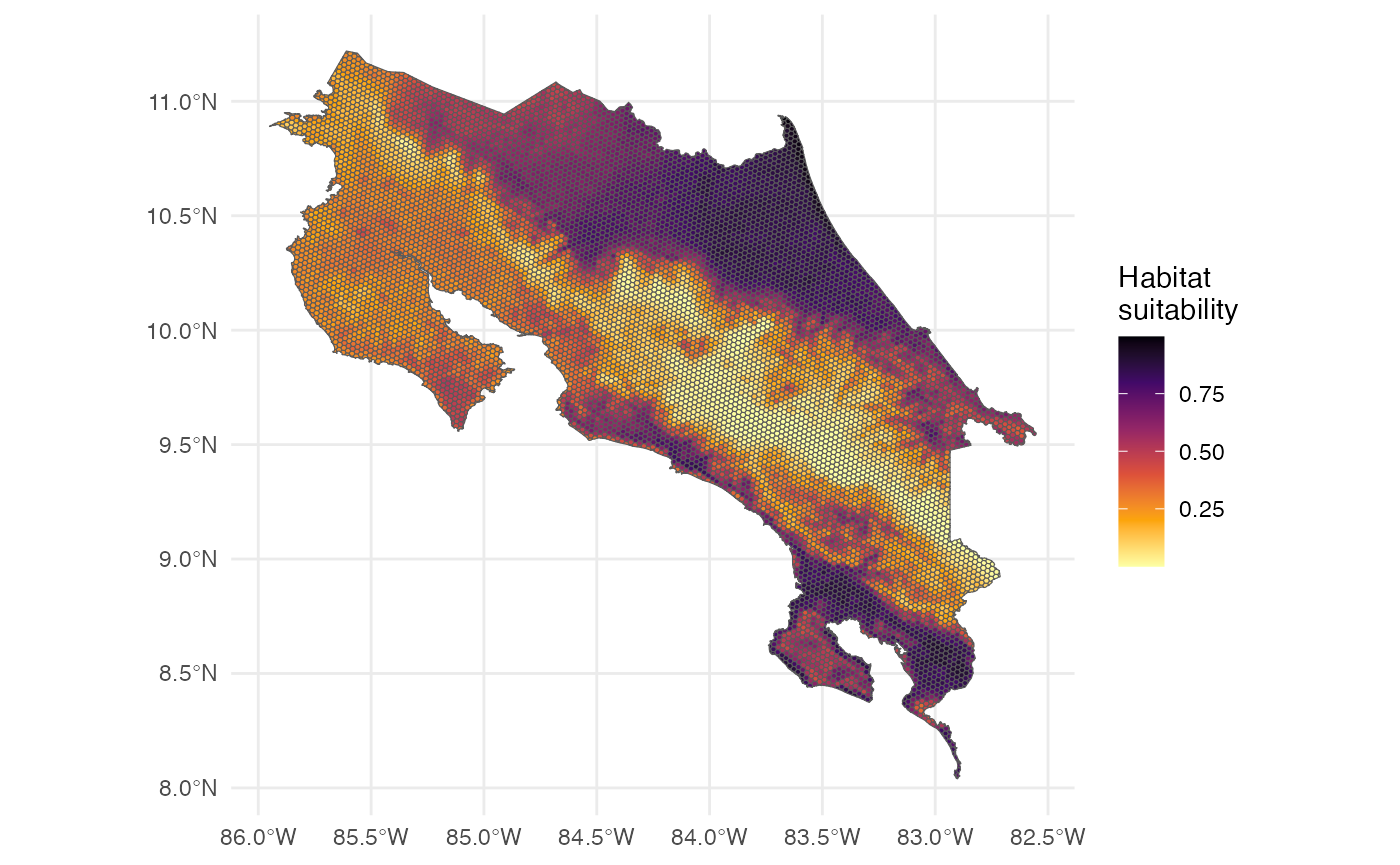
Conclusions
This vignette demonstrated a complete SDM workflow using
h3sdm, including data preparation with a hexagonal grid,
presence assignment, environmentally stratified pseudo-absence
generation, model fitting with spatial cross-validation, performance
evaluation, predictions, and variable importance analysis for both
current and future climate scenarios.